источник: https://dennybritz.com/posts/wildml/learning-to-trade-with-reinforcement-learning/
Сообщество исследователей в области глубокого обучения в основном держится в стороне от финансовых рынков. Возможно, это связано с тем, что у финансовой индустрии не самая лучшая репутация, проблема не кажется интересной с исследовательской точки зрения или с тем, что данные сложно и дорого получать.
В этой статье я буду утверждать, что обучение агентов с помощью метода обучения с подкреплением для торговли на финансовых (и криптовалютных) рынках может стать чрезвычайно интересной исследовательской задачей. Я считаю, что эта задача не получила должного внимания со стороны исследовательского сообщества, но может стать прорывом во многих смежных областях. Она во многом схожа с обучением агентов для многопользовательских игр, таких как DotA, и многие исследовательские задачи остаются актуальными. Практически ничего не зная о трейдинге, я последние несколько месяцев работал над проектом в этой области.
Это не пост о «прогнозировании цен с помощью глубокого обучения» Так что, если вы ищете примеры кода и моделей, вы можете быть разочарованы. Вместо этого я хочу поговорить на более высоком уровне о том, почему сложно научиться торговать с помощью машинного обучения, в чём заключаются некоторые проблемы и какую роль, по моему мнению, играет обучение с подкреплением. Если эта тема вызовет достаточный интерес, я могу опубликовать ещё один пост с конкретными примерами.
Я предполагаю, что у большинства читателей нет опыта в трейдинге, как и у меня, поэтому я начну с основ. Я ни в коем случае не эксперт, поэтому, пожалуйста, дайте мне знать в комментариях, если вы обнаружите ошибки. В этом посте я буду использовать криптовалюты в качестве примера, но те же принципы применимы к большинству финансовых рынков. Причина, по которой я использую криптовалюты, заключается в том, что данные бесплатны, общедоступны и легкодоступны. Любой может зарегистрироваться для торговли. Барьеры для торговли на финансовых рынках немного выше, а данные могут быть дорогими. И что ж, вокруг этого больше шумихи, так что это веселее!
Основы микроструктуры рынка
Торговля на криптовалютном (и большинстве финансовых) рынков происходит в рамках так называемого непрерывного двойного аукциона с открытой книгой заявок на бирже. Это просто завуалированное описание того, как покупатели и продавцы находят друг друга, чтобы торговать. За подбор пар отвечает биржа. Существует несколько десятков бирж, и на каждой из них могут быть представлены немного отличающиеся продукты (например, биткоин или Ethereum в сравнении с долларом США). С точки зрения интерфейса и предоставляемых данных все они выглядят примерно одинаково.
Давайте рассмотрим GDAX, одну из самых популярных бирж в США. Предположим, вы хотите торговать парой BTC-USD (биткоин за доллар США). Вы переходите на эту страницу и видите что-то вроде этого:
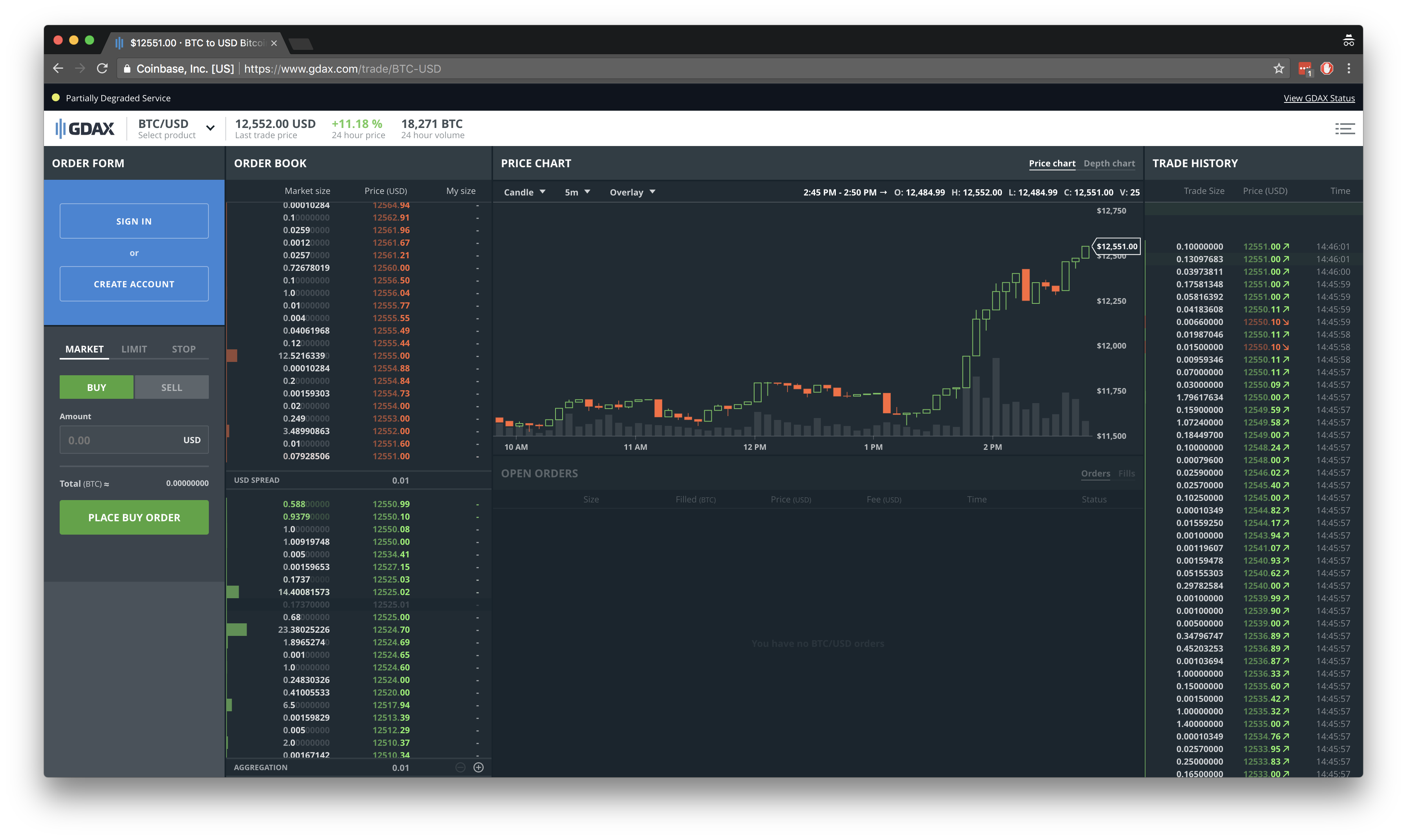
Здесь много информации, поэтому давайте рассмотрим основы:
Ценовой график (Средний)
Текущая цена — это цена последней сделки. Она меняется в зависимости от того, была ли это покупка или продажа (подробнее об этом ниже). График цен обычно отображается в виде свечного графика, на котором показаны цены открытия/начала (O), максимума (H), минимума (L) и закрытия/окончания (C) за определенный период времени. На изображении выше этот период составляет 5 минут, но вы можете изменить его с помощью раскрывающегося списка. Столбцы под графиком цен показывают объём (V) — общий объём всех сделок, совершённых за этот период. Объём важен, потому что он даёт представление о ликвидности рынка. Если вы хотите купить биткоин на 100 000 долларов, но никто не хочет его продавать, значит, рынок неликвиден. Вы просто не сможете купить. Большой объем торгов указывает на то, что многие люди готовы совершать сделки, а значит, вы, скорее всего, сможете купить или продать, когда захотите. Вообще говоря, чем больше денег вы хотите инвестировать, тем больший объем торгов вам нужен. Объем также указывает на «качество» ценового тренда. Большой объем означает, что вы можете больше полагаться на движение цены, чем при низком объеме. Высокий объём часто (но не всегда, как в случае с манипулированием рынком) является результатом консенсуса большого числа участников рынка.
История сделок (справа)
Справа отображается история всех недавних сделок. У каждой сделки есть размер, цена, временная метка и направление (покупка или продажа). Сделка — это соглашение между двумя сторонами: тейкером и мейкером. Подробнее об этом ниже.
Книга заказов (слева)
Слева показана книга заявок, в которой содержится информация о том, кто готов купить или продать актив по какой цене. Книга заявок состоит из двух частей: аск (также называемый предложением) и бид. Аск — это люди, готовые продать актив, а бид — люди, готовые его купить. По определению, лучший аск, то есть самая низкая цена, по которой кто-то готов продать актив, выше лучшей бид, то есть самой высокой цены, по которой кто-то готов его купить. Если бы это было не так, сделка между этими двумя сторонами уже состоялась бы. Разница между лучшим предложением купить и лучшим предложением продать называется спред.
Каждый уровень книги ордеров имеет цену и объём. Например, объём 2,0 при цене 10 000 долларов означает, что вы можете купить 2 BTC за 10 000 долларов. Если вы хотите купить больше, вам придётся заплатить более высокую цену за сумму, превышающую 2 BTC. Объём на каждом уровне является совокупным, то есть вы не знаете, сколько человек или ордеров составляют эти 2 BTC. Один человек может продавать 2 BTC, а 100 человек могут продавать по 0,02 BTC каждый (некоторые биржи предоставляют такую информацию, но большинство — нет). Давайте рассмотрим пример:
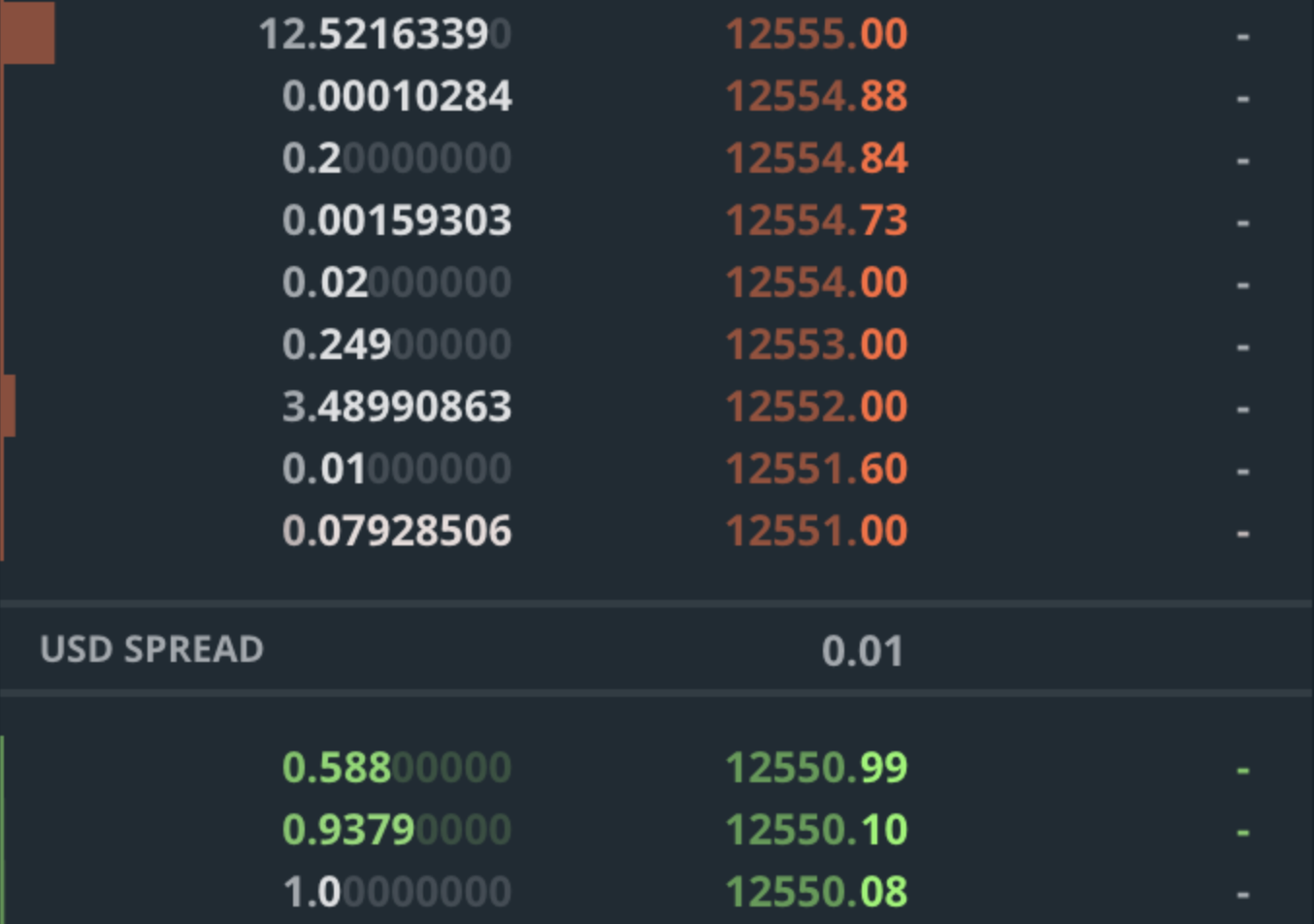
Итак, что произойдёт, если вы отправите заказ на покупку 3 BTC? Вы купите (округляя в большую сторону) 0,08 BTC по цене 12 551,00 доллара США, 0,01 BTC по цене 12 551,6 доллара США и 2,91 BTC по цене 12 552,00 доллара США. На GDAX вы также заплатите комиссию в размере 0,3 % за тейк-аут, что в сумме составит около 1.003 * (0.08 * 12551 + 0.01 * 12551.6 + 2.91 * 12552) = $37,768.88 и средняя цена за BTC составит 37768.88 / 3 = $12,589.62. Важно отметить, что сумма, которую вы фактически платите, намного превышает 12 551 доллар США, которые составляли текущую цену! Комиссия в размере 0,3 % на GDAX чрезвычайно высока по сравнению с комиссиями на финансовых рынках, а также намного выше комиссий многих других криптовалютных бирж, которые часто составляют от 0 % до 0,1 %.
Также обратите внимание, что ваш ордер на покупку поглотил весь объём, доступный на уровнях $12 551,00 и $12 551,60. Таким образом, книга ордеров «поднимется», и лучший аск станет $12 552,00. Текущая цена также станет $12 552,00, потому что именно по этой цене была совершена последняя сделка. Продажа осуществляется аналогичным образом, только теперь вы работаете с заявками на покупку в книге заявок и потенциально можете сдвинуть книгу заявок (и цену) вниз. Другими словами, размещая заявки на покупку и продажу, вы уменьшаете объём в книге заявок. Если ваши заявки достаточно крупные, вы можете сдвинуть книгу заявок на несколько уровней. На самом деле, если вы разместите очень крупную заявку на несколько миллионов долларов, вы значительно сдвинете книгу заявок и цену.
Как ордера попадают в книгу ордеров? В этом разница между рыночными и лимитными ордерами. В приведённом выше примере вы разместили рыночный ордер, который по сути означает «Купить/продать X количество BTC по наилучшей возможной цене прямо сейчас». Если вы не будете внимательно следить за тем, что происходит в книге ордеров, вы можете в итоге заплатить значительно больше, чем показывает текущая цена. Например, представьте, что на большинстве нижних уровней в книге ордеров доступен только объём в 0,001 BTC. Тогда большая часть вашего объёма на покупку будет удовлетворена по гораздо более высокой, более дорогой цене. Если вы отправляете лимитный ордер, также называемый пассивным ордером, вы указываете цену и количество, которые готовы купить или продать. Ордер будет добавлен в книгу, и вы сможете отменить его, пока он не был исполнен. Например, предположим, что цена биткоина составляет 10 000 долларов, но вы хотите продать его за 10 010 долларов. Вы размещаете лимитный ордер. Сначала ничего не происходит. Если цена продолжит снижаться, ваш ордер будет просто висеть в книге, ничего не делая, и никогда не будет исполнен. Вы можете отменить его в любой момент. Однако, если цена вырастет, ваш ордер в какой-то момент станет лучшим по цене в книге заявок, и следующий человек, который разместит рыночный ордер на достаточное количество акций, сравняется с ним по цене.
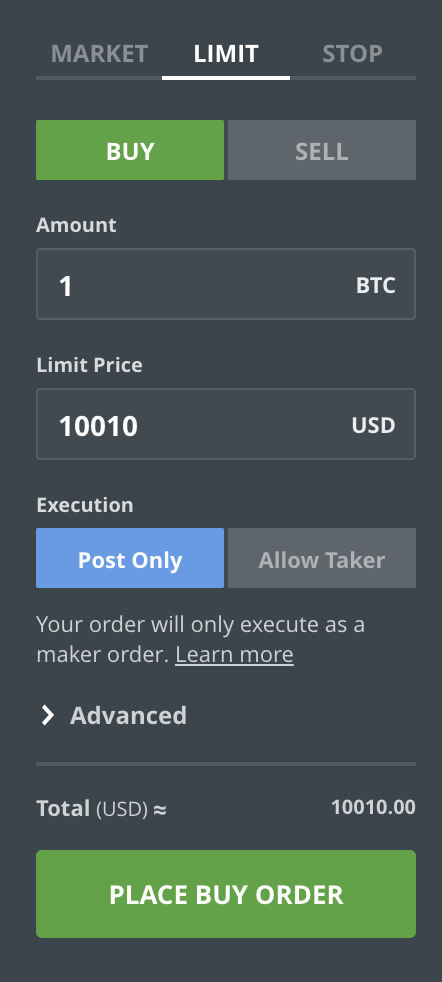
Рыночные ордера забирают ликвидность с рынка. Сопоставляя их с ордерами из книги ордеров, вы лишаете других людей возможности торговать — объём торгов уменьшается! По этой же причине рыночные ордера, или маркет-тейкеры, часто требуют более высокой комиссии, чем маркет-мейкеры, которые размещают ордера в книге. Лимитные ордера обеспечивают ликвидность, поскольку дают другим людям возможность торговать. В то же время лимитные ордера гарантируют, что вы не заплатите больше цены, указанной в лимитном ордере. Однако вы не знаете, когда и если вообще кто-то исполнит ваш ордер. Кроме того, вы сообщаете рынку, какой, по вашему мнению, должна быть цена. Это также может быть использовано для манипулирования другими участниками рынка, которые могут действовать определённым образом в зависимости от ордеров, которые вы исполняете или размещаете в книге заявок. Поскольку маркет-мейкеры предоставляют возможность торговать и раскрывают информацию, они обычно платят более низкие комиссии, чем маркет-тейкеры. Некоторые биржи также предоставляют стоп-ордера, которые позволяют устанавливать максимальную цену для рыночных ордеров.
Это было очень краткое введение в работу книг заявок и процесс сопоставления. Есть ещё много тонкостей, а также другие, гораздо более сложные типы заявок. Если вам что-то было непонятно, вы можете найти массу информации о механике работы книг заявок в интернете.
Данные
Основная причина, по которой я использую криптовалюты в этом посте, заключается в том, что данные общедоступны, бесплатны и их легко получить. Большинство бирж имеют потоковые API, которые позволяют получать обновления рынка в режиме реального времени. В качестве примера мы снова будем использовать GDAX (документация по API), но данные других бирж выглядят очень похоже. Давайте рассмотрим основные типы событий, которые можно использовать для построения модели машинного обучения.
Торговля
Произошла новая сделка. У каждой сделки есть временная метка, уникальный идентификатор, присвоенный биржей, цена, размер и сторона сделки, как описано выше. Если вы хотите построить график цен на актив, просто постройте график цен всех сделок. Если вы хотите построить свечной график, выделите торговые события за определенный период, например за пять минут, а затем постройте график для этих периодов.
{
"time": "2014-11-07T22:19:28.578544Z",
"trade_id": 74,
"price": "10.00000000",
"size": "0.01000000",
"side": "buy"
}
ОбноВление книги
Один или несколько уровней в книге ордеров были обновлены. Каждый уровень состоит из стороны (Buy = Bid, Sell = Ask), цены/уровня и нового количества на этом уровне. Обратите внимание, что это изменения, или дельты, и вам нужно самостоятельно создать полную книгу ордеров, объединив их.
{
"type": "l2update",
"product_id": "BTC-USD",
"changes": [
["buy", "10000.00", "3"],
["sell", "10000.03", "1"],
["sell", "10000.04", "2"],
["sell", "10000.07", "0"]
]
}
Книжный снимок
Аналогично BookUpdate, но представляет собой моментальный снимок всей книги ордеров. Поскольку полная книга ордеров может быть очень большой, вместо неё быстрее и эффективнее использовать события BookUpdate. Однако время от времени делать моментальный снимок может быть полезно.
{
"type": "snapshot",
"product_id": "BTC-EUR",
"bids": [["10000.00", "2"]],
"asks": [["10000.02", "3"]]
}
Это практически всё, что вам нужно знать о рыночных данных. Поток описанных выше событий содержит всю информацию, которую вы видели в графическом интерфейсе. Вы можете себе представить, как можно делать прогнозы на основе потока описанных выше событий.
Показатели торговой стратегии
При разработке торговых алгоритмов что вы оптимизируете? Очевидный ответ — прибыль, но это ещё не всё. Вам также нужно сравнить свою торговую стратегию с базовыми показателями, а также сравнить её риски и волатильность с другими инвестициями. Вот несколько основных показателей, которые используют трейдеры. Я не буду вдаваться в подробности, поэтому вы можете перейти по ссылкам, чтобы получить дополнительную информацию.
Чистая прибыль и убыток (Net PnL)
Проще говоря, это сумма, которую алгоритм зарабатывает (положительная величина) или теряет (отрицательная величина) за определённый период времени, за вычетом торговых комиссий.
Альфа и Бета
Альфа показывает, насколько ваша стратегия выгоднее с точки зрения прибыли по сравнению с альтернативными, относительно безрисковыми инвестициями, такими как государственные облигации. Даже если ваша стратегия прибыльна, возможно, вам выгоднее инвестировать в безрисковую альтернативу. Бета тесно связана с альфа и показывает, насколько волатильна ваша стратегия по сравнению с рынком. Например, бета, равная 0,5, означает, что ваши инвестиции меняются на 1 доллар, когда рынок меняется на 2 доллара.
Коэффициент Шарпа
Коэффициент Шарпа измеряет избыточную доходность на единицу принимаемого вами риска. По сути, это отношение доходности капитала к стандартному отклонению, скорректированное с учетом риска. Таким образом, чем выше значение, тем лучше. Коэффициент учитывает как волатильность вашей стратегии, так и альтернативную безрисковую инвестицию.
Максимальная Просадка
Максимальная просадка — это максимальная разница между локальным максимумом и последующим локальным минимумом, ещё один показатель риска. Например, максимальная просадка в 50 % означает, что в какой-то момент вы потеряете 50 % своего капитала. Чтобы вернуть первоначальную сумму капитала, вам нужно получить прибыль в размере 100 %. Очевидно, что чем меньше максимальная просадка, тем лучше.
Стоимость под риском (VaR)
Value at Risk — это показатель риска, который определяет, какую часть капитала вы можете потерять в течение определенного периода времени с некоторой вероятностью при условии, что рынок работает нормально. Например, 5-процентный VaR в размере 10 % за 1 день означает, что вероятность того, что вы потеряете более 10 % инвестиций в течение дня, составляет 5 %.
Контролируемое обучение
Прежде чем рассматривать проблему с точки зрения обучения с подкреплением, давайте разберёмся, как создать прибыльную торговую стратегию с помощью контролируемого обучения. Затем мы рассмотрим, в чём заключаются проблемы и почему мы можем захотеть использовать методы обучения с подкреплением.
Самый очевидный подход, который мы можем использовать, — это прогнозирование цен. Если мы можем предсказать, что рынок пойдёт вверх, мы можем купить сейчас и продать, когда рынок изменится. Или, что то же самое, если мы предсказываем, что рынок пойдёт вниз, мы можем открыть короткую позицию (взять взаймы актив, которым не владеем), а затем купить, когда рынок изменится. Однако здесь есть несколько проблем.
Во-первых, какую цену мы на самом деле прогнозируем? Как мы уже видели выше, мы покупаем не по «единой» цене. Окончательная цена, которую мы платим, зависит от объёма, доступного на разных уровнях книги заявок, и комиссий, которые нам нужно заплатить. Наивный подход — прогнозировать среднюю цену, которая является серединой между лучшей ценой покупки и лучшей ценой продажи. Так поступает большинство исследователей. Однако это всего лишь теоретическая цена, по которой мы не можем выполнять заказы. Она может значительно отличаться от реальной цены, которую мы платим.
Следующий вопрос — временной масштаб. Прогнозируем ли мы цену следующей сделки? Цену следующей секунды? Минуты? Часа? Дня? Интуитивно понятно, что чем дальше в будущее мы хотим заглянуть, тем больше неопределённости и тем сложнее становится задача прогнозирования.
Давайте рассмотрим пример. Предположим, что цена BTC составляет 10 000 долларов и мы можем точно предсказать, что в следующую минуту «цена» вырастет с 10 000 до 10 050 долларов. Значит ли это, что вы можете получить прибыль в размере 50 долларов, купив и продав актив? Давайте разберёмся, почему это не так.
- Мы покупаем, когда лучшая цена составляет 10 000 долларов. Скорее всего, мы не сможем купить все 1,0 BTC по этой цене, потому что в книге заявок нет необходимого объёма. Возможно, нам придётся купить 0,5 BTC по 10 000 долларов и 0,5 BTC по 10 010 долларов, то есть в среднем по 10 005 долларов. На GDAX мы также платим комиссию за тейкер в размере 0,3 %, что соответствует примерно 30 долларам.
- Как и ожидалось, цена сейчас составляет 10 050 долларов. Мы размещаем ордер на продажу. Поскольку рынок движется очень быстро, к тому времени, когда ордер будет доставлен по сети, цена уже снизится. Допустим, сейчас она составляет 10 045 долларов. Как и в предыдущем случае, мы, скорее всего, не сможем продать весь ваш 1 BTC по этой цене. Возможно, мы вынуждены продать 0,5 BTC по цене 10 045 долларов и 0,5 BTC по цене 10 040 долларов, то есть в среднем по цене 10 042,5 доллара. Затем мы платим ещё 0,3 % комиссии за принятие, что соответствует примерно 30 долларам.
Итак, сколько денег мы заработали? -10005 - 30 - 30 + 10,042.5 = -$22.5. Вместо того чтобы заработать 50 долларов, мы потеряли 22,5 доллара, хотя точно предсказали значительное движение цены в течение следующей минуты! В приведённом выше примере этому было три причины: отсутствие ликвидности на лучших уровнях книги заявок, задержки в сети и комиссии, которые контролируемая модель не могла учесть.
Какой из этого можно сделать вывод? Чтобы заработать на простой стратегии прогнозирования цен, мы должны прогнозировать относительно значительные колебания цен в течение более длительных периодов времени или очень грамотно подходить к комиссиям и управлению ордерами. А это очень сложная задача для прогнозирования. Мы могли бы сэкономить на комиссиях, используя лимитные ордера вместо рыночных, но тогда у нас не было бы гарантий, что наши ордера будут исполнены, и нам пришлось бы создавать сложную систему для управления ордерами и их отмены.
Но у обучения с учителем есть ещё одна проблема: оно не подразумевает политику. В приведённом выше примере мы купили, потому что прогнозировали рост цены, и она действительно выросла. Всё прошло по плану. Но что, если бы цена упала? Вы бы продали? Сохранили позицию и подождали? Что, если бы цена выросла совсем немного, а потом снова упала? Что, если бы мы не были уверены в прогнозе, например, на 65 % в сторону роста и на 35 % в сторону падения? Вы бы всё равно купили? Как вы выбираете порог для размещения заказа?
Таким образом, вам нужно нечто большее, чем просто модель прогнозирования цен (если только ваша модель не отличается исключительной точностью и надёжностью). Нам также нужна политика, основанная на правилах, которая будет принимать на вход ваши прогнозы цен и решать, что делать дальше: размещать ордер, ничего не делать, отменять ордер и так далее. Как разработать такую политику? Как оптимизировать параметры политики и пороговые значения для принятия решений? Ответ на этот вопрос неочевиден, и многие люди используют простые эвристические методы или полагаются на интуицию.
Типичный процесс разработки стратегии
К счастью, многие из вышеперечисленных проблем можно решить. Плохая новость заключается в том, что эти решения не очень эффективны. Давайте рассмотрим типичный процесс разработки торговой стратегии. Он выглядит примерно так:

- Анализ данных: вы проводите исследовательский анализ данных, чтобы найти возможности для торговли. Вы можете просматривать различные графики, рассчитывать статистические данные и так далее. Результатом этого этапа является «идея» торговой стратегии, которую необходимо проверить.
- Обучение модели с учителем: при необходимости вы можете обучить одну или несколько моделей обучения с учителем прогнозированию интересующих вас показателей, необходимых для работы стратегии. Например, прогнозированию цен, количества и т. д.
- Разработка политики: Затем вы создаёте политику на основе правил, которая определяет, какие действия следует предпринять, исходя из текущего состояния рынка и результатов работы контролируемых моделей. Обратите внимание, что у этой политики могут быть параметры, например пороговые значения для принятия решений, которые необходимо оптимизировать. Эта оптимизация выполняется позже.
- Тестирование стратегии на исторических данных: вы используете симулятор для тестирования первоначальной версии стратегии на основе исторических данных. Симулятор может учитывать такие факторы, как ликвидность книги ордеров, задержки в сети, комиссии и т. д. Если стратегия показывает хорошие результаты при тестировании на исторических данных, мы можем перейти к оптимизации параметров.
- Оптимизация параметров: теперь вы можете выполнить поиск, например с помощью метода перебора, по возможным значениям параметров стратегии, таким как пороговые значения или коэффициенты, снова используя симулятор и набор исторических данных. Здесь существует большой риск переобучения на исторических данных, поэтому необходимо тщательно подходить к использованию наборов для проверки и тестирования.
- Моделирование и торговля на демо-счете: перед запуском стратегии проводится моделирование на основе новых рыночных данных в режиме реального времени. Это называется торговлей на демо-счете, и она помогает избежать переобучения. Стратегия запускается в реальной среде только в том случае, если она успешно работает на демо-счете.
- Торговля в реальном времени: стратегия теперь работает в реальном времени на бирже.
Это сложный процесс. Он может немного отличаться в зависимости от компании или исследователя, но обычно происходит что-то в этом роде при разработке новых торговых стратегий. Так почему же я считаю, что этот процесс неэффективен? На то есть несколько причин.
- Циклы итераций выполняются медленно. Шаги 1–3 в значительной степени основаны на интуиции, и вы не узнаете, работает ли ваша стратегия, пока не выполните оптимизацию на шагах 4–5, что может вынудить вас начать с нуля. На самом деле каждый шаг сопряжён с риском неудачи и необходимостью начинать с нуля.
- Моделирование проводится слишком поздно. Вы не учитываете напрямую такие факторы окружающей среды, как задержки, комиссии и ликвидность, вплоть до шага 4. Разве эти факторы не должны напрямую влиять на разработку вашей стратегии или параметры вашей модели?
- Политики разрабатываются независимо от моделей с учителем, хотя они тесно взаимосвязаны. Прогнозы с учителем являются исходными данными для политики. Разве не имеет смысла оптимизировать их совместно?
- Правила просты. Они ограничены тем, что могут придумать люди.
- Оптимизация параметров неэффективна. Например, предположим, что вы оптимизируете соотношение прибыли и риска и хотите найти параметры, которые обеспечат вам высокий коэффициент Шарпа. Вместо того чтобы использовать эффективный подход на основе градиента, вы выполняете неэффективный поиск по сетке и надеетесь, что найдёте что-то подходящее (без переобучения).
Давайте посмотрим, как метод обучения с подкреплением может помочь решить большинство этих проблем.
Глубокое обучение с подкреплением для трейдинга
Помните, что традиционная задача обучения с подкреплением может быть сформулирована как марковский процесс принятия решений (МППР). У нас есть агент, действующий в среде. На каждом временном шаге tt агент получает на входе текущее состояние StSt, совершает действие AtAt и получает вознаграждение Rt+1Rt+1 и следующее состояние St+1St+1. Агент выбирает действие на основе некоторой политики ππ: At=π(St)At=π(St). Наша цель — найти политику, которая максимизирует совокупное вознаграждение ∑Rt∑Rt за некоторый конечный или бесконечный период времени.
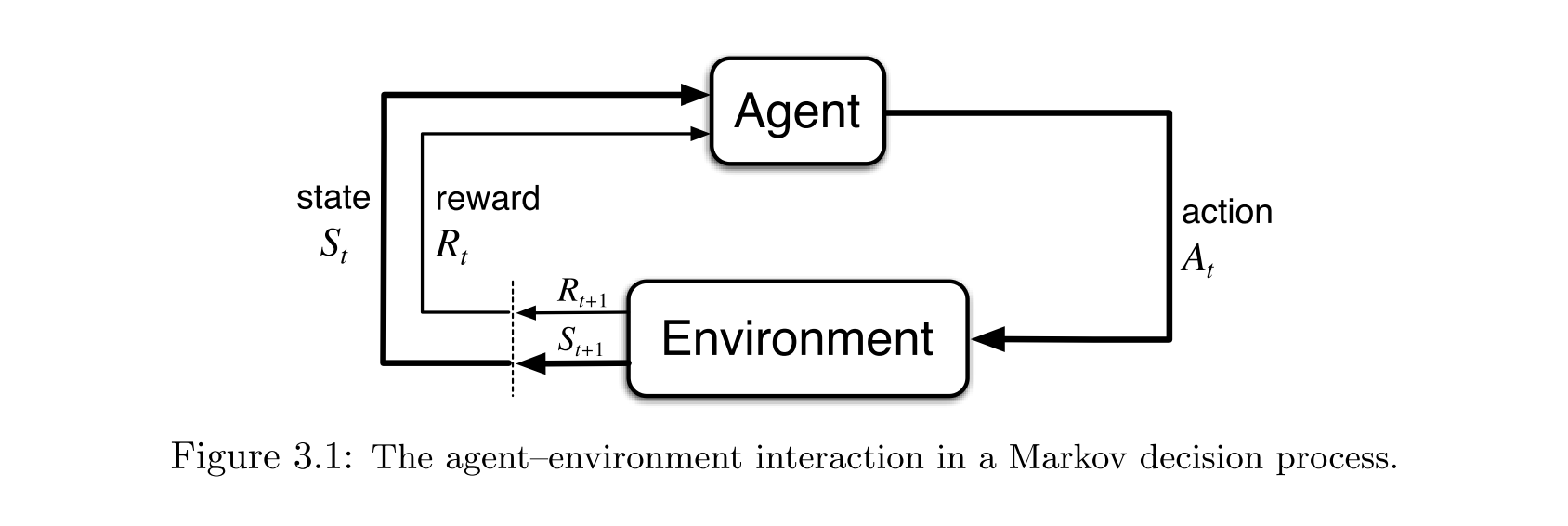
Давайте попробуем разобраться, что означают эти символы в контексте трейдинга.
Агент
Давайте начнём с самого простого. Агент — это наш торговый агент. Вы можете представить себе агента как трейдера-человека, который открывает графический интерфейс биржи и принимает торговые решения на основе текущего состояния биржи и своего счёта.
Окружающая среда
Здесь всё немного сложнее. Очевидным ответом было бы то, что биржа — это наша среда. Но важно отметить, что на той же бирже торгует множество других агентов, как людей, так и алгоритмических игроков. Давайте на минутку представим, что мы совершаем действия с минимальной задержкой (подробнее об этом ниже). Мы совершаем какое-то действие, ждём минуту, получаем новое состояние, совершаем ещё одно действие и так далее. Когда мы наблюдаем за новым состоянием, это является реакцией рыночной среды, которая включает в себя реакцию других агентов. Таким образом, с точки зрения нашего агента, эти агенты также являются частью среды. Мы не можем их контролировать.
Однако, объединяя других агентов в одну большую сложную среду, мы теряем возможность явно моделировать их. Например, можно представить, что мы научились реконструировать алгоритмы и стратегии других трейдеров, а затем научились их использовать. Это поставило бы нас перед задачей многоагентного обучения с подкреплением (Multi-Agent Reinforcement Learning, MARL), которая активно исследуется. Подробнее об этом я расскажу ниже. Для простоты предположим, что мы этого не делаем и взаимодействуем с единой сложной средой, которая включает в себя поведение всех остальных агентов.
Состояние
В случае торговли на бирже мы не наблюдаем за всем состоянием окружающей среды. Например, мы не знаем, сколько в ней других агентов, каковы их балансы или открытые лимитные ордера. Это означает, что мы имеем дело с частично наблюдаемым марковским процессом принятия решений (ЧНМПР). Агент наблюдает не за фактическим состоянием StSt окружающей среды, а за его производной. Давайте назовём это наблюдением XtXt, которое вычисляется с помощью некоторой функции полного состояния Xt∼O(St)Xt∼O(St).
В нашем случае наблюдение на каждом временном этапе tt — это просто история всех биржевых событий (описанных в разделе «Данные» выше), произошедших до момента tt. Эту историю событий можно использовать для определения текущего состояния биржи. Однако для того, чтобы наш агент мог принимать решения, наблюдение должно включать в себя ещё несколько параметров, таких как текущий баланс счёта и открытые лимитные ордера, если таковые имеются.
Временная Шкала
Нам нужно решить, в каком временном масштабе мы хотим действовать. Дни? Часы? Минуты? Секунды? Миллисекунды? Наносекунды? Переменные масштабы? Все это требует разных подходов. Тот, кто покупает актив и держит его в течение нескольких дней, недель или месяцев, часто делает долгосрочную ставку на основе анализа, например: «Будет ли биткоин успешным?». Часто такие решения обусловлены внешними событиями, новостями или фундаментальным пониманием стоимости или потенциала активов. Поскольку такой анализ обычно требует понимания того, как устроен мир, его может быть сложно автоматизировать с помощью методов машинного обучения. С другой стороны, существуют методы высокочастотной торговли (HFT), в которых решения почти полностью основаны на сигналах микроструктуры рынка. Решения принимаются в наносекундном масштабе, а торговые стратегии используют выделенные соединения с биржами и чрезвычайно быстрые, но простые алгоритмы, работающие на аппаратном обеспечении FPGA. Эти две крайности можно рассматривать с точки зрения «человечности». В первом случае требуется целостное представление и понимание того, как устроен мир, человеческая интуиция и анализ высокого уровня, а во втором — простое, но чрезвычайно быстрое сопоставление с образцом.
Нейронные сети популярны, потому что при наличии большого объёма данных они могут обучаться более сложным представлениям, чем такие алгоритмы, как линейная регрессия или наивный байесовский классификатор. Но глубокие нейронные сети относительно медленны. Они не могут делать прогнозы в наносекундном масштабе и, следовательно, не могут конкурировать по скорости с алгоритмами высокочастотного трейдинга. Поэтому я считаю, что золотая середина находится где-то посередине между этими двумя крайностями. Мы хотим действовать в масштабе времени, когда мы можем анализировать данные быстрее, чем это возможно для человека, но при этом быть умнее позволяет нам превзойти «быстрые, но простые” алгоритмы. Мое предположение, и это действительно всего лишь предположение, состоит в том, что это соответствует действию во временных масштабах где-то между несколькими миллисекундами и несколькими минутами. Трейдеры-люди также могут действовать в этих временных масштабах, но не так быстро, как алгоритмы. И они, конечно, не могут синтезировать тот же объем информации, что алгоритм, за тот же период времени. В этом наше преимущество.
Ещё одна причина действовать в относительно коротких временных рамках заключается в том, что закономерности в данных могут быть более очевидными. Например, поскольку большинство трейдеров-людей используют одни и те же (ограниченные) графические пользовательские интерфейсы с заранее заданными рыночными сигналами (такими как сигнал MACD, встроенный во многие графические пользовательские интерфейсы бирж), их действия ограничены информацией, содержащейся в этих сигналах, что приводит к определённым шаблонам действий. Аналогичным образом алгоритмы, работающие на рынке, действуют на основе определённых шаблонов. Мы надеемся, что алгоритмы глубокого обучения с подкреплением смогут выявить эти шаблоны и использовать их.
Обратите внимание, что мы также можем действовать в разных временных масштабах в зависимости от какого-либо триггера. Например, мы можем принять решение о совершении сделки всякий раз, когда на рынке происходит крупная сделка. Такой агент, работающий по принципу триггера, всё равно будет примерно соответствовать определённому временному масштабу в зависимости от частоты срабатывания триггера.
Пространство Действия
В обучении с подкреплением мы проводим различие между дискретными (конечными) и непрерывными (бесконечными) пространствами действий. В зависимости от того, насколько сложным мы хотим сделать нашего агента, у нас есть несколько вариантов. Самый простой подход — использовать три действия: «Купить», «Держать» и «Продать». Это работает, но ограничивает нас в размещении рыночных ордеров и инвестировании детерминированной суммы денег на каждом этапе. Следующий уровень сложности — позволить нашему агенту учиться определять, сколько денег инвестировать, например, на основе неопределённости нашей модели. Это приведёт нас к непрерывному пространству действий, поскольку нам нужно будет определиться как с (дискретным) действием, так и с (непрерывным) количеством. Ещё более сложный сценарий возникает, когда мы хотим, чтобы наш агент мог размещать лимитные ордера. В этом случае наш агент должен определить уровень (цену) и количество ордера, которые являются непрерывными величинами. Он также должен иметь возможность отменять открытые ордера, которые ещё не были исполнены.
Функция Вознаграждения
Это ещё один сложный вопрос. Мы можем выбрать одну из нескольких возможных функций вознаграждения. Очевидной является реализованная прибыль или убыток (прибыль и убыток). Агент получает вознаграждение всякий раз, когда закрывает позицию, например, когда продаёт актив, который ранее купил, или покупает актив, который ранее взял взаймы. чистая прибыль от этой сделки может быть положительной или отрицательной. Это и есть сигнал вознаграждения. По мере того как агент максимизирует общее совокупное вознаграждение, он учится торговать с прибылью. Эта функция вознаграждения технически верна и в пределе приводит к оптимальной политике. Однако вознаграждения выдаются редко, поскольку действия по покупке и продаже совершаются относительно редко по сравнению с бездействием. Следовательно, агент должен обучаться без частого получения обратной связи.
Альтернативой с более частой обратной связью может быть нереализованный PnL, то есть чистая прибыль, которую агент получил бы, если бы немедленно закрыл все свои позиции. Например, если цена упала после того, как агент разместил ордер на покупку, он получит отрицательное вознаграждение, даже если ещё не продал. Поскольку нереализованный PnL может меняться на каждом временном шаге, агент получает более частые сигналы обратной связи. Однако прямая обратная связь может склонять агента к краткосрочным действиям, если используется в сочетании с коэффициентом затухания.
Обе эти функции вознаграждения наивно оптимизированы для получения прибыли. На самом деле трейдер может стремиться минимизировать риск. Стратегия с чуть меньшей доходностью, но значительно меньшей волатильностью предпочтительнее высоковолатильной, но лишь немного более прибыльной стратегии. Использование коэффициента Шарпа — один из простых способов учесть риск, но есть и другие. Мы также можем учитывать что-то вроде максимальной просадки, описанной выше. Можно представить себе широкий спектр сложных функций вознаграждения, которые обеспечивают компромисс между прибылью и риском.
Аргументы в пользу обучения с подкреплением
Теперь, когда мы имеем представление о том, как можно использовать обучение с подкреплением в трейдинге, давайте разберёмся, почему мы хотим использовать именно этот метод, а не контролируемое обучение. Разработка торговых стратегий с использованием обучения с подкреплением выглядит примерно так. Это намного проще и логичнее, чем подход, который мы рассматривали в предыдущем разделе.
Комплексная оптимизация того, что для нас важно
При традиционном подходе к разработке стратегии мы должны пройти несколько этапов, прежде чем получим метрику, которая нас действительно интересует. Например, если мы хотим найти стратегию с максимальной просадкой в 25 %, нам нужно обучить модель с учителем, разработать политику на основе правил с использованием этой модели, протестировать политику на исторических данных и оптимизировать её гиперпараметры, а затем оценить её эффективность с помощью моделирования.
Обучение с подкреплением позволяет проводить сквозную оптимизацию и максимизировать (потенциально отложенные) вознаграждения. Добавив параметр в функцию вознаграждения, мы можем, например, напрямую оптимизировать этот спад, не прибегая к отдельным этапам. Например, можно представить себе, что при спаде более чем на 25 % агент получает большое отрицательное вознаграждение, что заставляет его искать другую стратегию. Конечно, мы можем комбинировать спад со многими другими важными для вас показателями. Это не только более простая, но и гораздо более мощная модель.
Изученные Стратегии
Вместо того чтобы вручную разрабатывать политику, основанную на правилах, обучение с подкреплением позволяет напрямую изучать политику. Нам не нужно указывать правила и пороговые значения, например «покупайте, если вы более чем на 75 % уверены, что рынок будет расти». Это заложено в политике обучения с подкреплением, которая оптимизируется по интересующему нас показателю. Мы исключаем целый этап из процесса разработки стратегии! А поскольку политика может быть параметризована с помощью сложной модели, такой как глубокая нейронная сеть, мы можем разработать политику, которая будет более сложной и эффективной, чем любые правила, которые мог бы придумать трейдер-человек. Как мы уже видели выше, политика неявно учитывает такие показатели, как риск, если мы оптимизируем именно его.
Обучение непосредственно в симуляционных средах
Нам нужно было провести отдельное тестирование на исторических данных и оптимизировать параметры, поскольку при использовании контролируемого подхода нашим стратегиям было сложно учитывать внешние факторы, такие как ликвидность книги ордеров, структура комиссий, задержки и другие. Нередко бывает так, что вы разрабатываете стратегию, а потом выясняется, что она не работает, возможно, из-за слишком высоких задержек или слишком быстрого движения рынка, из-за чего вы не можете совершать сделки, на которые рассчитывали.
Поскольку агенты обучения с подкреплением обучаются в симуляции, которая может быть настолько сложной, насколько вы захотите, с учётом задержек, ликвидности и комиссий, у нас нет этой проблемы! Обход ограничений среды — часть процесса оптимизации. Например, если мы смоделируем задержку в среде обучения с подкреплением и в результате агент совершит ошибку, он получит отрицательное вознаграждение, что заставит его научиться обходить задержки.
Мы могли бы пойти дальше и смоделировать реакцию других агентов в той же среде, например, чтобы оценить влияние наших собственных ордеров. Если действия агента влияют на цену в симуляции, основанной на исторических данных, мы не знаем, как на это отреагировал бы реальный рынок. Как правило, симуляторы игнорируют это и предполагают, что ордера не оказывают влияния на рынок. Однако, изучив модель среды и выполнив пробные запуски с использованием таких методов, как поиск по дереву Монте-Карло (Monte Carlo Tree Search, MCTS), мы могли бы учесть потенциальную реакцию рынка (других агентов). Грамотно используя данные, которые мы получаем из реальной среды, мы можем постоянно совершенствовать нашу модель. Здесь существует интересный компромисс между исследованием и эксплуатацией: действуем ли мы в реальной среде оптимально, чтобы получать прибыль, или неоптимально, чтобы собрать интересную информацию, которую мы можем использовать для улучшения модели нашей среды и других агентов?
Это очень мощная концепция. Создавая всё более сложную среду для моделирования, которая воспроизводит реальный мир, вы можете обучать очень продвинутых агентов, которые учатся учитывать ограничения среды.
Учимся адаптироваться к рыночным условиям
Интуитивно понятно, что одни стратегии и тактики будут работать лучше в одних рыночных условиях, чем в других. Например, стратегия может быть эффективной в условиях медвежьего рынка, но приводить к убыткам в условиях бычьего рынка. Отчасти это связано с упрощённым характером стратегии, которая не имеет достаточной параметризации, чтобы адаптироваться к меняющимся рыночным условиям.
Поскольку RL-агенты обучаются с помощью мощных политик, параметризованных нейронными сетями, они также могут адаптироваться к различным рыночным условиям, анализируя исторические данные, при условии, что они обучаются в течение длительного времени и имеют достаточный объём памяти. Это позволяет им быть гораздо более устойчивыми к изменениям на рынке. На самом деле мы можем напрямую оптимизировать их, чтобы они были устойчивы к изменениям рыночных условий, добавив соответствующие штрафы в функцию вознаграждения.
Возможность моделировать других агентов
Уникальная особенность обучения с подкреплением заключается в том, что мы можем явно учитывать других агентов. До сих пор мы всегда говорили о том, «как реагирует рынок», игнорируя тот факт, что рынок — это всего лишь группа агентов и алгоритмов, таких же, как мы. Однако если мы явно смоделируем других агентов в среде, наш агент сможет научиться использовать их стратегии. По сути, мы переформулируем задачу с «прогнозирования рынка» на «использование агентов». Это гораздо больше похоже на то, что мы делаем в многопользовательских играх, таких как DotA.
Аргументы в пользу исследования торговых агентов
Цель этой статьи — не только познакомить вас с методом обучения с подкреплением в трейдинге, но и убедить других исследователей обратить внимание на эту проблему. Давайте посмотрим, что делает трейдинг интересной исследовательской задачей.
Живое тестирование и быстрый цикл итераций
При обучении агентов с помощью метода обучения с подкреплением часто бывает сложно или дорого развернуть их в реальном мире и получить обратную связь. Например, если вы обучили агента играть в Starcraft 2, как вы заставите его играть против большего количества игроков-людей? То же самое касается шахмат, покера и любой другой игры, популярной в сообществе RL. Скорее всего, вам нужно будет каким-то образом принять участие в турнире и позволить вашему агенту играть там.
Торговые агенты обладают характеристиками, очень похожими на те, что есть у многопользовательских игр. Но вы можете легко протестировать их в реальных условиях! Вы можете запустить своего агента на бирже через API и сразу же получить обратную связь от реального рынка. Если ваш агент не обобщает данные и теряет деньги, значит, вы, вероятно, слишком привязаны к обучающим данным. Другими словами, цикл итераций может быть очень быстрым.
Большие Многопользовательские среды
Торговая среда — это, по сути, многопользовательская игра, в которой одновременно действуют тысячи агентов. Это активно развивающаяся область исследований. Сейчас мы добиваемся успехов в многопользовательских играх, таких как покер, Dota2 и других, и многие из этих методов применимы и здесь. На самом деле задача трейдинга гораздо сложнее из-за огромного количества одновременно действующих агентов, которые могут выйти из игры или присоединиться к ней в любой момент. Понимание того, как создавать модели других агентов, — это лишь одно из возможных направлений исследований. Как упоминалось ранее, можно выполнять действия в реальной среде, чтобы получить как можно больше информации о том, каким правилам следуют другие агенты.
Учимся использовать других агентов и манипулировать рынком
С этим тесно связан вопрос о том, можем ли мы научиться использовать других агентов, действующих в окружающей среде. Например, если бы мы точно знали, какие алгоритмы используются на рынке, мы могли бы заставить их совершать действия, которые им не следует совершать, и извлечь выгоду из их ошибок. Это относится и к трейдерам-людям, которые обычно действуют на основе комбинации хорошо известных рыночных сигналов, таких как экспоненциальные скользящие средние или давление в книге ордеров.
Отказ от ответственности: не позволяйте своему агенту совершать противоправные действия! Соблюдайте все применимые законы в вашей юрисдикции. И наконец, прошлые результаты не гарантируют будущих.
Скудные награды и исследования
Торговые агенты обычно получают от рынка небольшое вознаграждение. Большую часть времени вы будете бездействовать. Действия по покупке и продаже обычно составляют лишь малую часть всех ваших действий. Наивное применение алгоритмов обучения с подкреплением, «жадных» до вознаграждения, обречено на провал. Это открывает возможности для новых алгоритмов и методов, особенно основанных на моделях, которые могут эффективно работать с небольшими вознаграждениями.
Аналогичный аргумент можно привести в пользу исследования. Многие современные стандартные алгоритмы, такие как DQN или A3C, используют очень наивный подход к исследованию, по сути добавляя случайный шум в политику. Однако в случае с трейдингом большинство состояний в среде являются неблагоприятными, и лишь некоторые из них можно назвать благоприятными. При наивном случайном подходе к исследованию почти никогда не будут найдены благоприятные пары состояний и действий. Здесь необходим новый подход.
Мультиагентная самоигра
Подобно тому, как автоигра применяется в играх для двух игроков, таких как шахматы или го, методы автоигры можно применять в многопользовательской среде. Например, можно представить, что одновременно обучается большое количество конкурирующих агентов, и исследовать, похожа ли результирующая динамика рынка на динамику реального мира. Можно также комбинировать типы обучаемых агентов, используя разные алгоритмы обучения с подкреплением, эволюционные и детерминированные алгоритмы. Можно также использовать реальные рыночные данные в качестве контролируемого сигнала обратной связи, чтобы «заставить» агентов в симуляции вести себя так же, как в реальном мире.
Непрерывное Время
Поскольку рынки меняются в масштабах от микросекунд до миллисекунд, область трейдинга является хорошим приближением к области непрерывного времени. В приведенном выше примере мы зафиксировали временной интервал и приняли это решение за агента. Однако можно представить, что эта часть обучения агента будет автоматизирована. Таким образом, агент будет решать не только о том, какие действия предпринимать, но и когда их предпринимать. Опять же, это активно развивающаяся область исследований, полезная для многих других сфер, включая робототехнику.
Нестационарное обучение на протяжении всей жизни и катастрофическое забывание
Торговая среда по своей сути нестационарна. Рыночные условия меняются, другие агенты присоединяются, уходят и постоянно меняют свои стратегии. Можем ли мы обучить агентов, которые научатся автоматически подстраиваться под меняющиеся рыночные условия, не «забывая» при этом то, чему они научились раньше? Например, может ли агент успешно перейти от «медвежьего» рынка к «бычьему», а затем снова к «медвежьему» рынку без необходимости переобучения? Может ли агент подстраиваться под других агентов и автоматически учиться использовать их?
Трансферное обучение и вспомогательные задачи
Обучение с подкреплением с нуля в сложных областях может занять очень много времени, поскольку агентам нужно не только научиться принимать правильные решения, но и усвоить «правила игры».
Существует множество способов ускорить обучение агентов с подкреплением, в том числе трансферное обучение и использование вспомогательных задач. Например, можно предварительно обучить агента с помощью экспертной политики или добавить вспомогательные задачи, такие как прогнозирование цен, к цели обучения агента, чтобы ускорить процесс.
Leave a reply
You must be logged in to post a comment.