Archive for 2 августа, 2025
источник: https://www.anthropic.com/engineering/building-effective-agents
Мы работали с десятками команд, создающих агентов LLM в разных отраслях. Как правило, в наиболее успешных реализациях используются простые, составные шаблоны, а не сложные фреймворки.
За последний год мы поработали с десятками команд, которые создавали агентов на основе больших языковых моделей (LLM) в различных отраслях. Как правило, наиболее успешные реализации не использовали сложные фреймворки или специализированные библиотеки. Вместо этого они применяли простые, компонуемые шаблоны.
В этой статье мы делимся опытом работы с клиентами и создания агентов, а также даём практические советы разработчикам по созданию эффективных агентов.
Что такое агенты?
Понятие «агент» можно трактовать по-разному. Некоторые клиенты определяют агентов как полностью автономные системы, которые работают независимо в течение длительного времени, используя различные инструменты для выполнения сложных задач. Другие используют этот термин для описания более директивных реализаций, которые следуют заранее заданным рабочим процессам. В Anthropic мы относим все эти варианты к агентным системам, но проводим важное архитектурное различие между рабочими процессами и агентами:
- Рабочие процессы — это системы, в которых LLM и инструменты управляются с помощью предопределенных путей кода.
- Агенты, с другой стороны, представляют собой системы, в которых LLM динамически управляют своими собственными процессами и использованием инструментов, сохраняя контроль над тем, как они выполняют задачи.
Ниже мы подробно рассмотрим оба типа агентных систем. В Приложении 1 («Агенты на практике») мы описываем две сферы, в которых клиенты нашли особую ценность в использовании таких систем.
Когда (и когда не стоит) использовать агентов
При создании приложений с использованием LLMS мы рекомендуем находить максимально простое решение и увеличивать сложность только при необходимости. Это может означать, что агентские системы вообще не будут создаваться. Агентские системы часто обменивают задержку и затраты на повышение производительности задачи, и вам следует подумать, когда этот компромисс имеет смысл.
Там, где требуется большая сложность, рабочие процессы обеспечивают предсказуемость и согласованность при выполнении чётко определённых задач, в то время как агенты являются лучшим вариантом, когда требуется гибкость и принятие решений на основе модели в больших масштабах. Однако для многих приложений достаточно оптимизировать отдельные вызовы LLM с помощью примеров поиска и контекстных примеров.
Когда и как использовать фреймворки
Существует множество фреймворков, которые упрощают внедрение агентных систем, в том числе:
- LangGraph из LangChain;
- Платформа для ИИ-агентов от Amazon Bedrock
- Rivet — конструктор рабочих процессов LLM с графическим интерфейсом и функцией перетаскивания; и
- Vellum — ещё один инструмент с графическим интерфейсом для создания и тестирования сложных рабочих процессов.
Эти фреймворки упрощают начало работы, упрощая стандартные низкоуровневые задачи, такие как вызов LLM, определение и синтаксический анализ инструментов, а также объединение вызовов в цепочку. Однако они часто создают дополнительные уровни абстракции, которые могут скрывать базовые подсказки и ответы, затрудняя их отладку. Они также могут вызвать соблазн добавить сложности, когда было бы достаточно более простой настройки.
Мы рекомендуем разработчикам начинать с непосредственного использования API LLM: многие шаблоны можно реализовать с помощью нескольких строк кода.
Если вы используете фреймворк, убедитесь, что понимаете его базовый код.
Неверные предположения о том, что происходит «под капотом», часто приводят к ошибкам клиентов.
Примеры реализации можно найти в нашей кулинарной книге https://github.com/anthropics/anthropic-cookbook/tree/main/patterns/agents
Строительные блоки, рабочие процессы и агенты
В этом разделе мы рассмотрим распространённые шаблоны агентских систем, которые мы наблюдали в процессе работы. Мы начнём с нашего основного строительного блока — расширенной языковой модели — и будем постепенно увеличивать сложность, от простых композиционных рабочих процессов до автономных агентов.
Строительный блок: расширенная LLM
Основным строительным блоком agentic systems является LLM, дополненный такими дополнениями, как поиск, инструменты и память. Наши текущие модели могут активно использовать эти возможности — генерировать свои собственные поисковые запросы, выбирать соответствующие инструменты и определять, какую информацию сохранять.
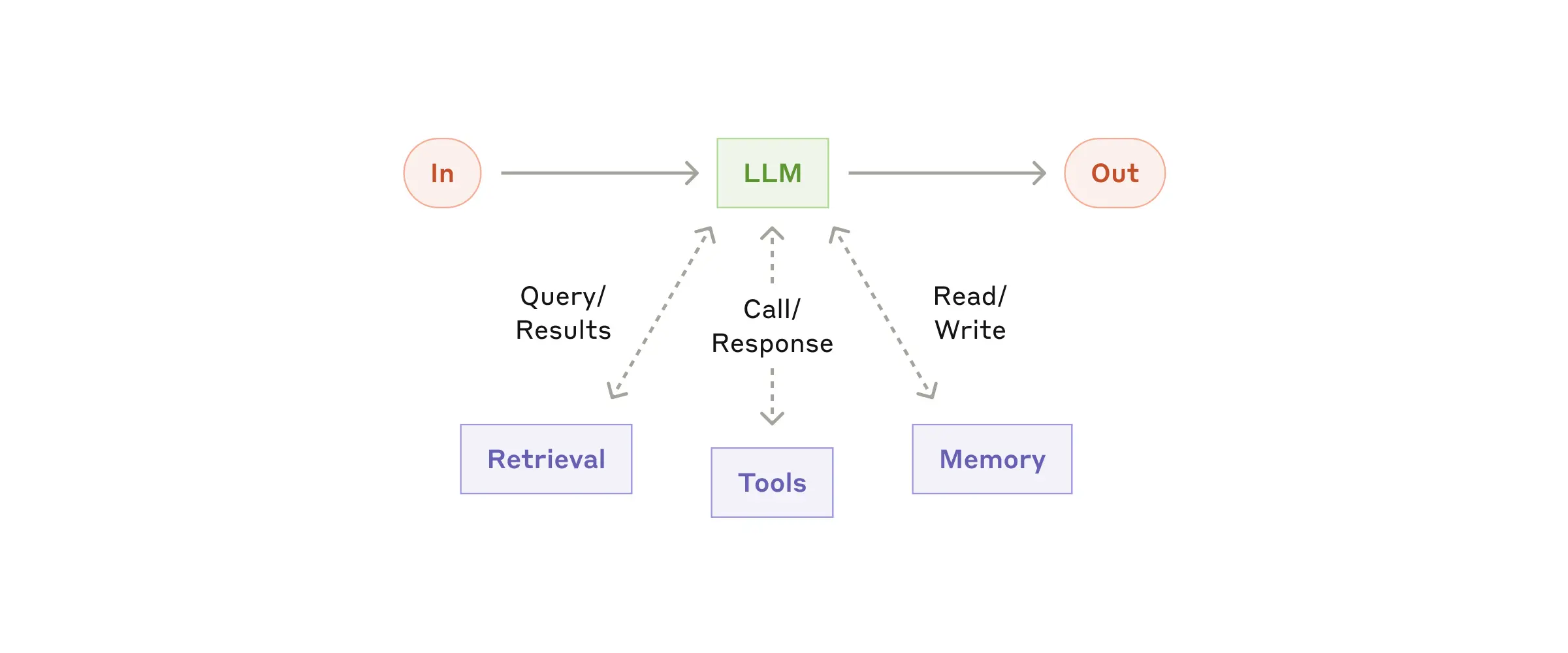
Мы рекомендуем сосредоточиться на двух ключевых аспектах реализации: адаптировать эти возможности под ваш конкретный сценарий использования и обеспечить простой и хорошо документированный интерфейс для вашей языковой модели. Существует множество способов реализовать эти дополнения, но один из них — недавно выпущенный протокол контекста модели, который позволяет разработчикам интегрироваться с растущей экосистемой сторонних инструментов с помощью простой клиентской реализации.
В оставшейся части статьи мы будем исходить из того, что каждый вызов LLM имеет доступ к этим расширенным возможностям.
Рабочий процесс: Объединение запросов в цепочку
Цепочка подсказок разбивает задачу на последовательность шагов, где каждый вызов LLM обрабатывает результат предыдущего. Вы можете добавить программные проверки (см. «шлюз» на схеме ниже) на любых промежуточных этапах, чтобы убедиться, что процесс идёт по плану.
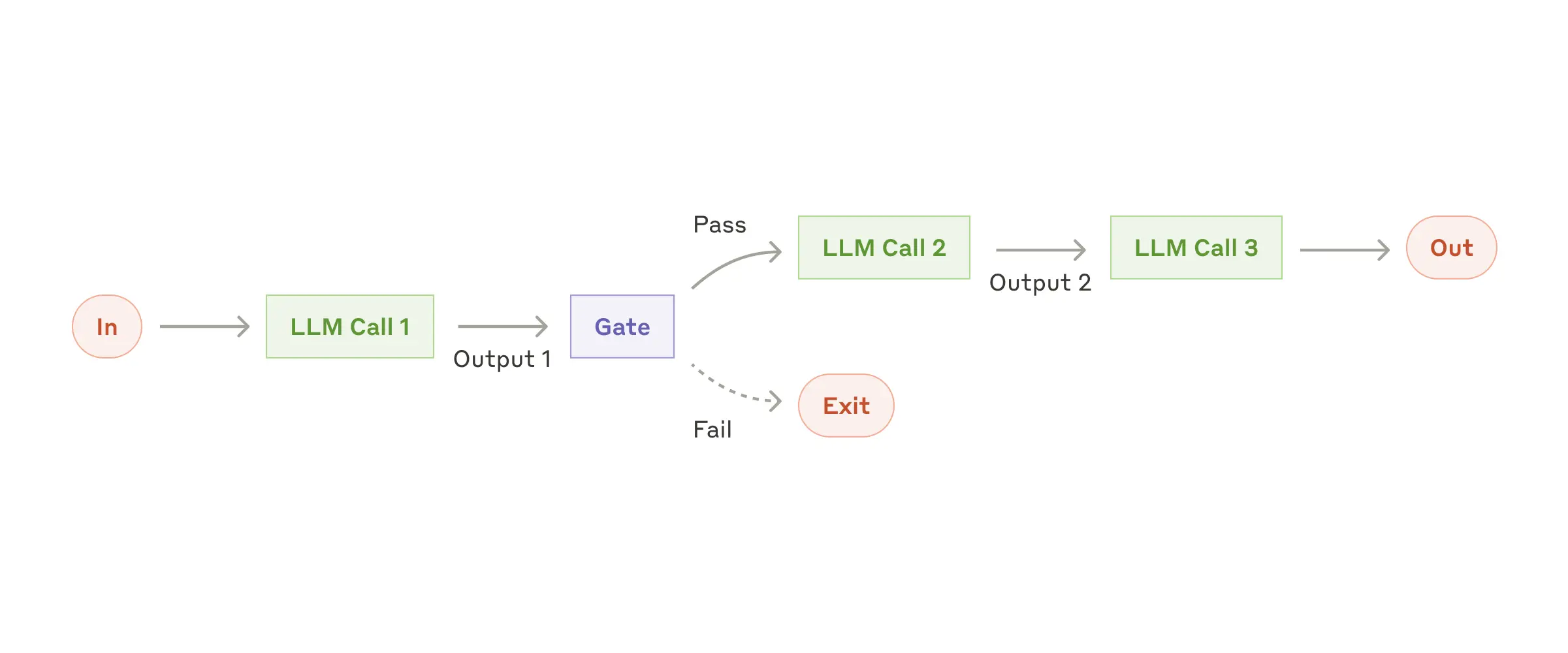
Когда использовать этот рабочий процесс: Этот рабочий процесс идеально подходит для ситуаций, когда задачу можно легко и чётко разделить на фиксированные подзадачи. Основная цель — снизить задержку и повысить точность, чтобы каждый вызов LLM выполнял более простую задачу.
Примеры ситуаций, в которых полезна цепочка подсказок:
- Создание маркетингового текста с последующим переводом на другой язык.
- Составление плана документа, проверка соответствия плана определённым критериям, а затем написание документа на основе плана.
Рабочий процесс: Маршрутизация
Маршрутизация классифицирует входные данные и направляет их на выполнение специализированной последующей задачи. Такой рабочий процесс позволяет разделить задачи и создавать более специализированные запросы. Без этого рабочего процесса оптимизация для одного типа входных данных может негативно сказаться на производительности при работе с другими типами входных данных.
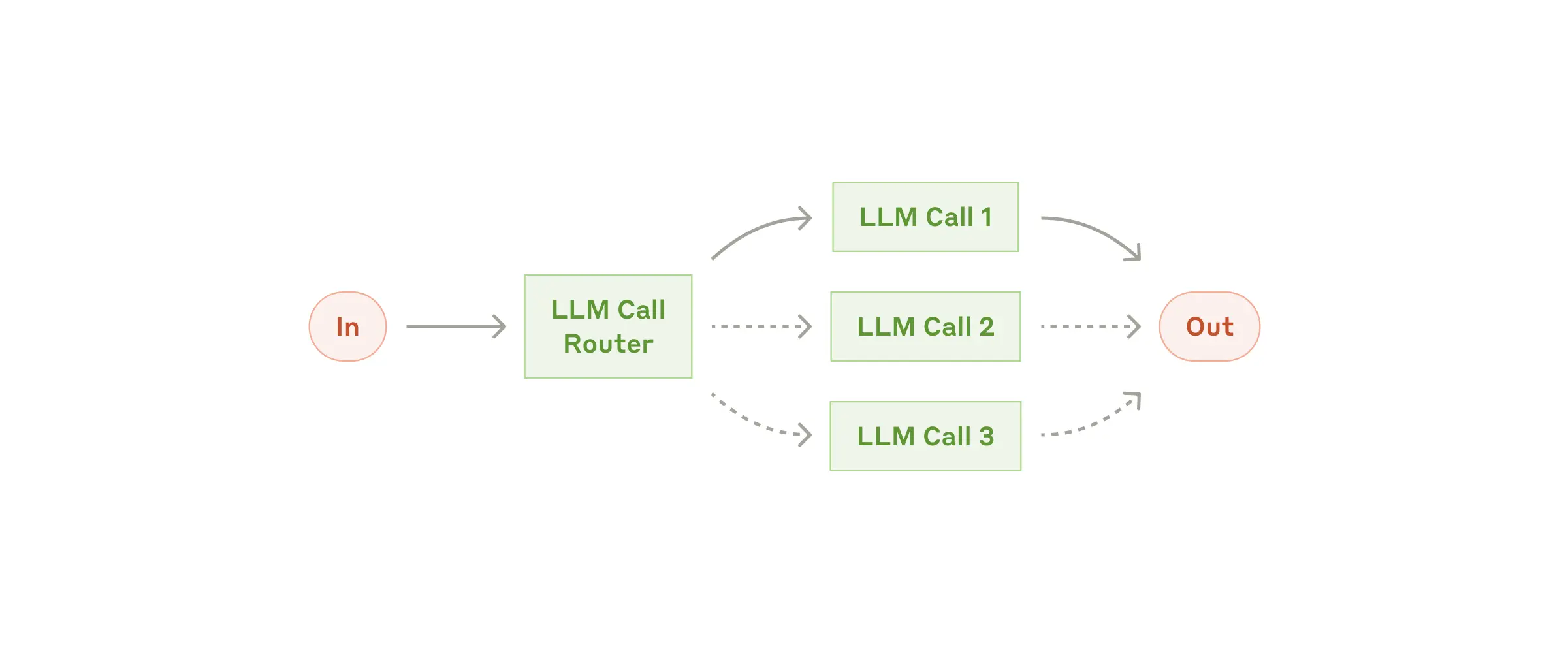
Когда следует использовать этот рабочий процесс: Маршрутизация хорошо подходит для сложных задач, в которых есть отдельные категории, которые лучше обрабатывать по отдельности, а классификация может быть выполнена точно с помощью языковой модели или более традиционной модели/алгоритма классификации.
Примеры ситуаций, в которых полезна маршрутизация:
- Распределение различных типов запросов в службу поддержки (общие вопросы, запросы на возврат средств, техническая поддержка) по разным последующим процессам, подсказкам и инструментам.
- Для оптимизации затрат и скорости мы направляем простые/стандартные вопросы в менее мощные модели, такие как Claude 3.5 Haiku, а сложные/нестандартные вопросы — в более мощные модели, такие как Claude 3.5 Sonnet.
Рабочий процесс: Распараллеливание
Иногда большие языковые модели могут одновременно работать над задачей, а их результаты объединяются программным способом. Этот процесс, называемый распараллеливанием, реализуется двумя основными способами:
- Разделение на этапы: разбиение задачи на независимые подзадачи, выполняемые параллельно.
- Голосование: Выполнение одной и той же задачи несколько раз для получения различных результатов.
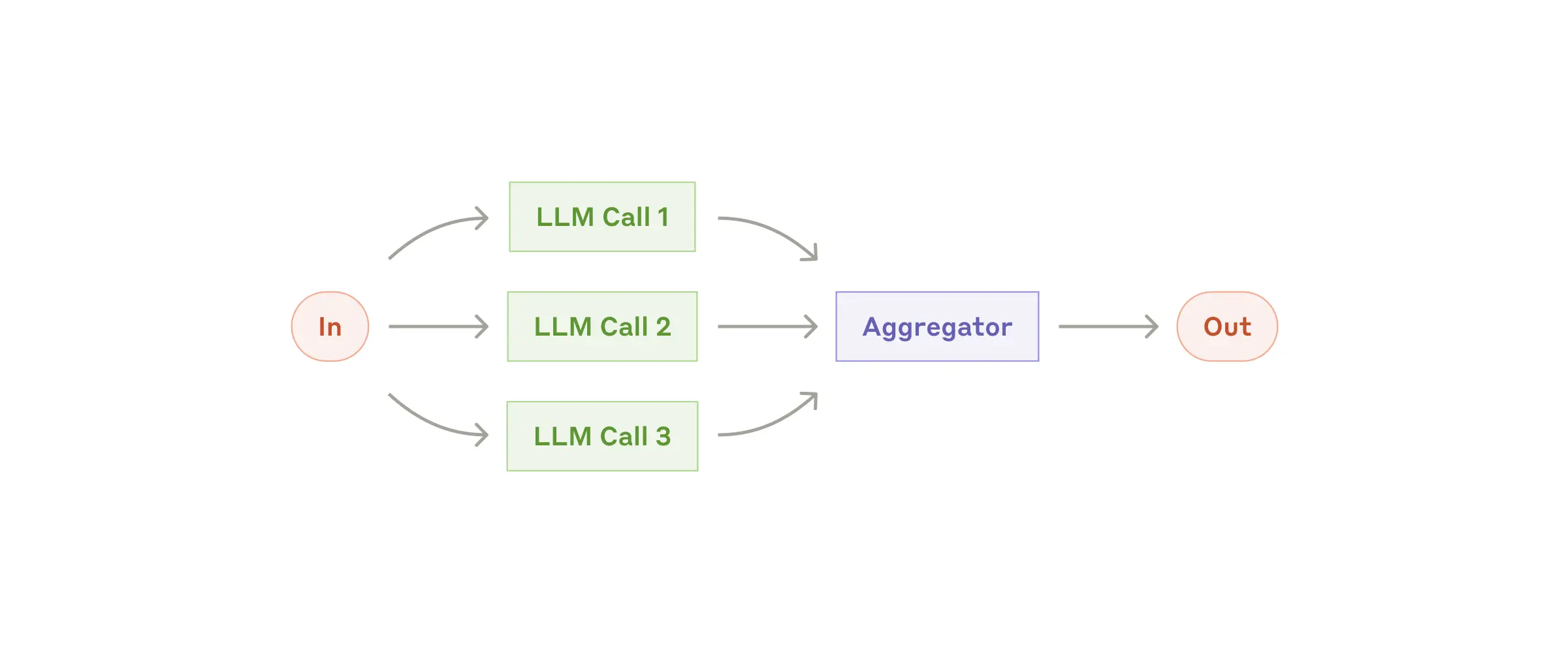
Когда использовать этот рабочий процесс: Распараллеливание эффективно, когда разделенные подзадачи могут быть распараллелены для повышения скорости или когда для получения более достоверных результатов требуется несколько точек зрения или попыток. Для сложных задач с несколькими соображениями LLM обычно работают лучше, когда каждое соображение обрабатывается отдельным вызовом LLM, что позволяет сосредоточить внимание на каждом конкретном аспекте.
Примеры ситуаций, в которых полезна распараллеливание:
- Секционирование:
- Внедрение защитных механизмов, при которых один экземпляр модели обрабатывает запросы пользователей, а другой проверяет их на наличие неприемлемого контента или запросов. Такой подход, как правило, более эффективен, чем использование одного и того же вызова LLM для защитных механизмов и основного ответа.
- Автоматизация evals для оценки производительности LLM, при которой каждый вызов LLM оценивает различные аспекты производительности модели в заданном запросе.
- Голосование:
- Проверка фрагмента кода на наличие уязвимостей, при которой несколько различных инструментов проверяют код и помечают его, если находят проблему.
- Оценка уместности того или иного фрагмента контента с помощью нескольких подсказок, оценивающих разные аспекты, или с использованием разных пороговых значений для голосования, чтобы сбалансировать количество ложноположительных и ложноотрицательных результатов.
Рабочий процесс: оркестратор и исполнители
В рабочем процессе orchestrator-workers центральный LLM динамически разбивает задачи, делегирует их рабочим LLM и синтезирует их результаты.
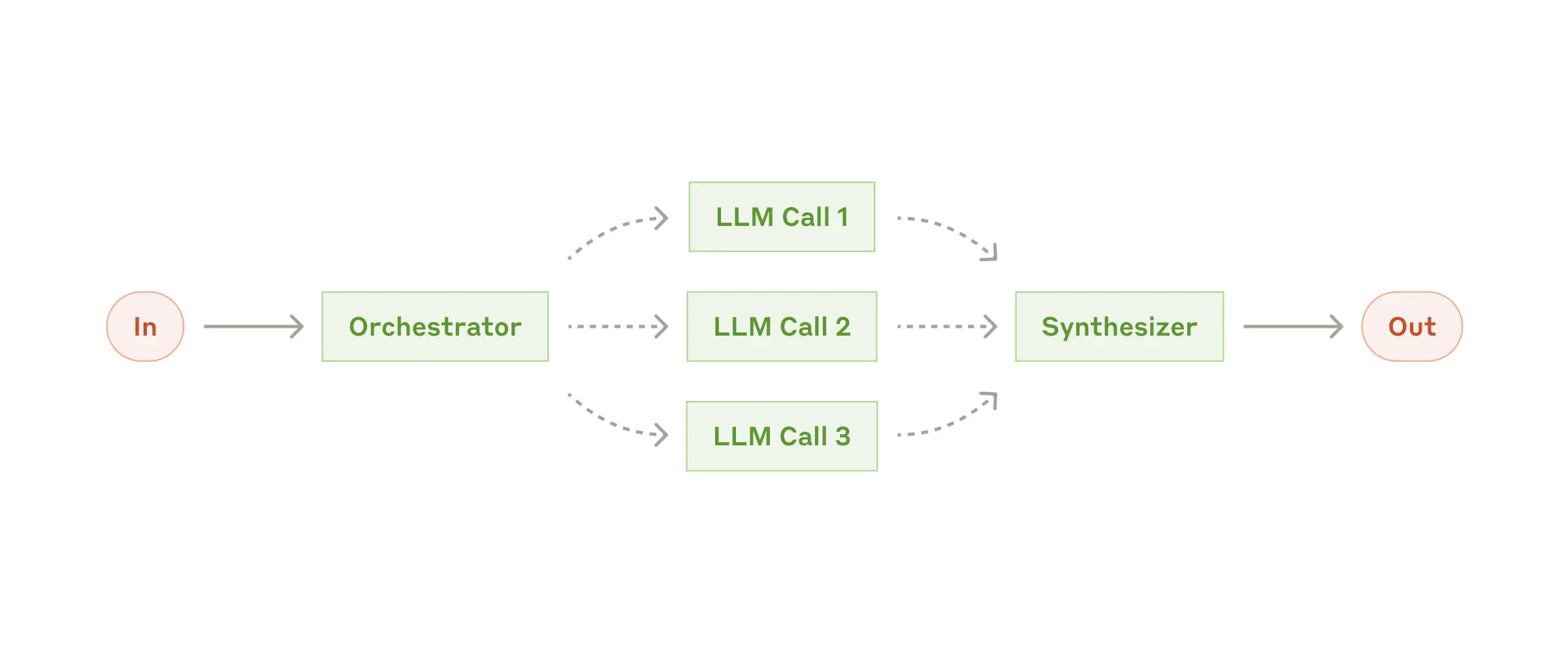
Когда использовать этот рабочий процесс: Этот рабочий процесс хорошо подходит для сложных задач, в которых невозможно предугадать, какие подзадачи потребуются (например, при написании кода количество файлов, которые необходимо изменить, и характер изменений в каждом файле, скорее всего, будут зависеть от задачи). Несмотря на топографическое сходство, ключевое отличие от распараллеливания заключается в гибкости: подзадачи не определены заранее, а определяются оркестратором на основе конкретных входных данных.
Пример использования orchestrator-workers:
- Продукты для программирования, которые каждый раз вносят сложные изменения в несколько файлов.
- Поисковые задачи предполагают сбор и анализ информации из нескольких источников для поиска возможных вариантов.
Рабочий процесс: оценщик-оптимизатор
В процессе работы оценщика-оптимизатора один вызов LLM генерирует ответ, а другой обеспечивает оценку и обратную связь в цикле.
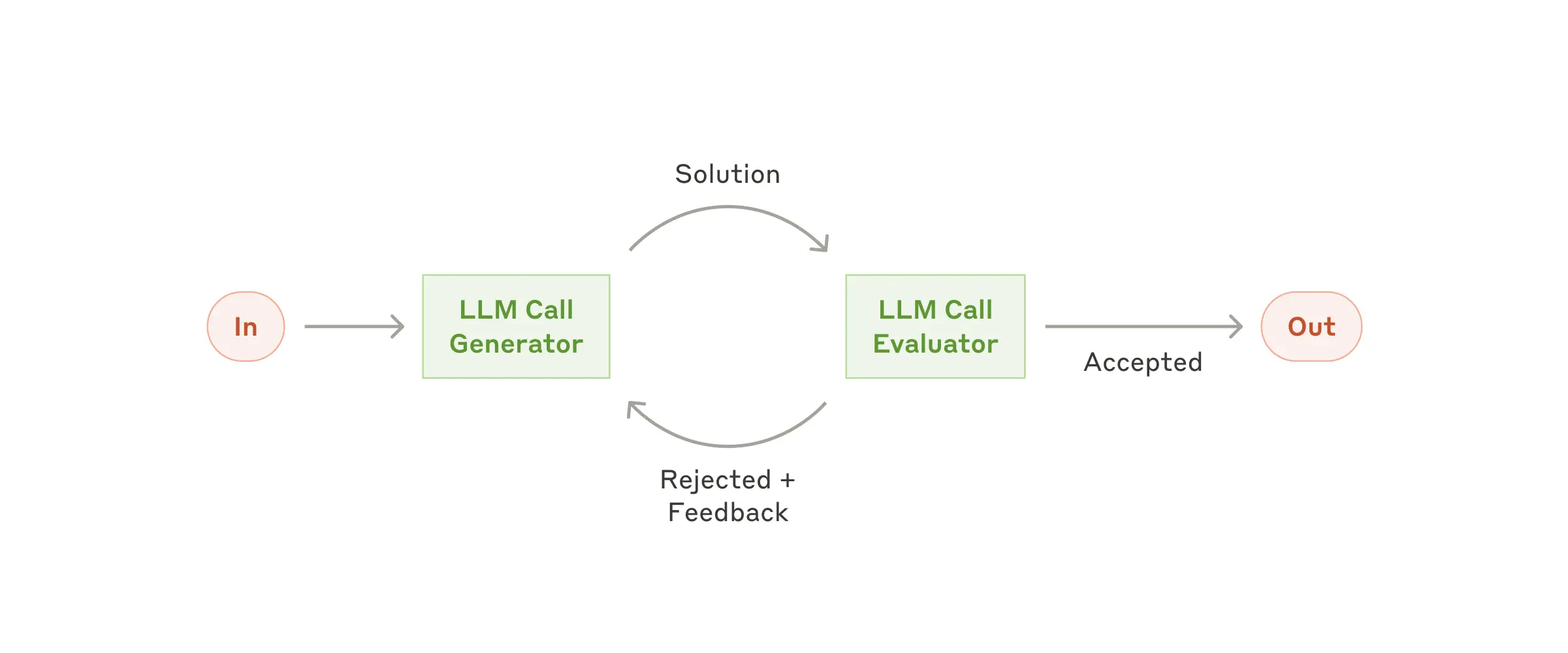
Когда использовать этот рабочий процесс: Этот рабочий процесс особенно эффективен, когда у нас есть чёткие критерии оценки и когда итеративное доработка даёт ощутимый результат. Два признака того, что процесс подходит: во-первых, ответы LLM можно значительно улучшить, если человек сформулирует свои замечания; во-вторых, LLM может предоставить такие замечания. Это похоже на итеративный процесс написания текста, через который проходит автор, чтобы создать безупречный документ.
Примеры ситуаций, в которых полезен оценщик-оптимизатор:
- Литературный перевод, в котором есть нюансы, которые LLM-переводчик может не уловить с первого раза, но которые LLM-редактор может оценить и дать полезные комментарии.
- Сложные поисковые задачи, требующие многократного поиска и анализа для получения полной информации, в ходе которых специалист принимает решение о целесообразности дальнейшего поиска.
Агенты
Агенты появляются в производстве по мере того, как LLM развивают ключевые возможности — понимание сложных входных данных, участие в рассуждениях и планировании, надежное использование инструментов и восстановление после ошибок. Агенты начинают свою работу либо с команды пользователя-человека, либо с интерактивного обсуждения с ним. Как только задача становится ясной, агенты планируют и действуют независимо, потенциально возвращаясь к человеку за дополнительной информацией или суждением. Во время выполнения задачи агентам крайне важно получать «исходную информацию» от среды на каждом этапе (например, результаты вызова инструмента или выполнения кода), чтобы оценивать прогресс. Затем агенты могут приостанавливаться для получения обратной связи от человека на контрольных точках или при возникновении препятствий. Задача часто завершается по достижении результата, но также часто используются условия остановки (например, максимальное количество итераций) для сохранения контроля.
Агенты могут выполнять сложные задачи, но их реализация зачастую проста. Как правило, это просто большие языковые модели, использующие инструменты, основанные на обратной связи с окружающей средой. Поэтому крайне важно разрабатывать наборы инструментов и их документацию чётко и продуманно. Подробнее о передовых методах разработки инструментов мы рассказываем в Приложении 2 («Разработка инструментов с помощью подсказок»).
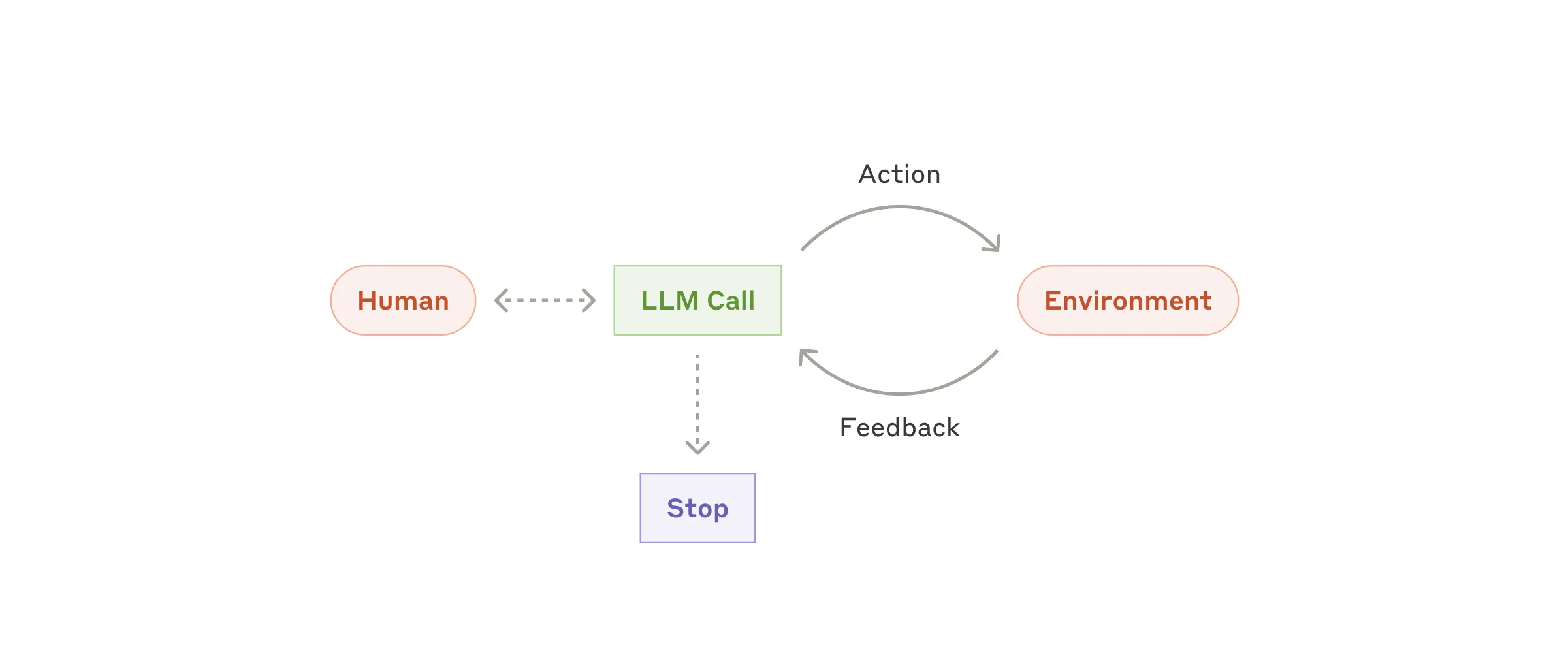
Когда использовать агентов: Агенты могут использоваться для решения задач с открытым финалом, когда сложно или невозможно предсказать необходимое количество шагов и когда нельзя жестко запрограммировать фиксированный путь. Языковая модель потенциально может работать в течение многих циклов, и вы должны в некоторой степени доверять ее решениям. Автономность агентов делает их идеальными для масштабирования задач в доверенных средах.
Автономность агентов означает более высокие затраты и вероятность возникновения ошибок. Мы рекомендуем проводить тщательное тестирование в изолированных средах с соответствующими ограничениями.
Примеры ситуаций, в которых полезны агенты:
Ниже приведены примеры из наших собственных реализаций:
- Агент по кодированию для решения задач SWE-bench, которые предполагают внесение изменений во множество файлов на основе описания задачи;
- Наша эталонная реализация с использованием компьютера, в которой Клод использует компьютер для выполнения задач.
Комбинируем и настраиваем эти шаблоны
Эти строительные блоки не являются обязательными. Это распространённые шаблоны, которые разработчики могут изменять и комбинировать в соответствии с различными сценариями использования. Ключ к успеху, как и в случае с любыми другими функциями LLM, — это оценка производительности и итеративная доработка реализаций. Повторим: вам следует рассматривать возможность усложнения только в том случае, если это явно улучшит результаты.
Краткие сведения
Успех в сфере LLM заключается не в создании самой сложной системы. Речь идет о создании правильной системы для ваших нужд. Начните с простых подсказок, оптимизируйте их с помощью комплексной оценки и добавляйте многоступенчатые агентские системы только тогда, когда более простых решений не хватает.
При внедрении агентов мы стараемся следовать трём основным принципам:
- Сохраняйте простоту в дизайне вашего агента.
- Отдавайте приоритет прозрачности, наглядно демонстрируя этапы планирования агента.
- Тщательно продумайте интерфейс между агентом и компьютером (ACI), подробно описав инструменты и проведя тестирование.
Фреймворки могут помочь вам быстро приступить к работе, но не бойтесь сокращать количество уровней абстракции и использовать базовые компоненты при переходе к продакшену. Следуя этим принципам, вы сможете создавать не только мощные, но и надёжные, удобные в обслуживании и заслуживающие доверия пользователей агенты.
Благодарности
Авторы: Эрик Шлунц и Барри Чжан. Эта работа основана на нашем опыте создания агентов в Anthropic и на ценных идеях, которыми поделились наши клиенты, за что мы им глубоко признательны.
Приложение 1. Агенты на практике
В ходе работы с клиентами мы выявили два особенно перспективных варианта применения ИИ-агентов, которые демонстрируют практическую ценность описанных выше шаблонов. Оба варианта показывают, что агенты наиболее эффективны при выполнении задач, требующих как общения, так и действий, имеющих чёткие критерии успеха, обеспечивающих обратную связь и предполагающих значимый контроль со стороны человека.
A. Служба поддержки клиентов
Служба поддержки клиентов сочетает в себе привычные интерфейсы чат-ботов с расширенными возможностями благодаря интеграции инструментов. Это оптимальное решение для агентов, работающих в режиме свободного общения, поскольку:
- Взаимодействие со службой поддержки естественным образом вписывается в ход беседы, но при этом требует доступа к внешней информации и выполнения действий;
- Можно интегрировать инструменты для получения данных о клиентах, истории заказов и статей из базы знаний;
- Такие действия, как возврат средств или обновление билетов, можно выполнять программно; и
- Успех можно чётко измерить с помощью поставленных пользователем целей.
Несколько компаний продемонстрировали жизнеспособность этого подхода с помощью моделей ценообразования, основанных на использовании, которые предполагают оплату только за успешные решения проблем, что свидетельствует об уверенности в эффективности работы их агентов.
B. Кодирующие агенты
Сфера разработки программного обеспечения продемонстрировала значительный потенциал для функций LLM, с развитием возможностей от завершения кода до автономного решения проблем. Агенты особенно эффективны, потому что:
- Кодовые решения можно проверить с помощью автоматизированных тестов;
- Агенты могут корректировать решения, используя результаты тестирования в качестве обратной связи;
- Проблемное поле чётко определено и структурировано; и
- Качество продукции можно оценить объективно.
В нашей собственной реализации агенты теперь могут решать реальные проблемы GitHub в тесте SWE-bench Verified только на основе описания запроса на вытягивание. Однако, несмотря на то, что автоматизированное тестирование помогает проверить функциональность, проверка человеком по-прежнему важна для обеспечения соответствия решений более широким системным требованиям.
Приложение 2. Быстрое создание инструментов
Независимо от того, какую агентную систему вы создаёте, инструменты, скорее всего, будут важной частью вашего агента. Инструменты позволяют Claude взаимодействовать с внешними сервисами и API, задавая их точную структуру и определение в нашем API. Когда Claude отвечает, он включает блок использования инструмента в ответ API, если планирует вызвать инструмент. Определениям и спецификациям инструментов следует уделять не меньше внимания при разработке подсказок, чем самим подсказкам. В этом кратком приложении мы описываем, как разрабатывать подсказки для ваших инструментов.
Часто существует несколько способов указать одно и то же действие. Например, вы можете указать изменение файла, написав diff, или переписать весь файл. Для структурированного вывода можно вернуть код в формате Markdown или в формате JSON. В разработке программного обеспечения подобные различия носят косметический характер и могут быть преобразованы из одного формата в другой без потери данных. Однако некоторые форматы гораздо сложнее для больших языковых моделей, чем другие. Для написания diff необходимо знать, сколько строк изменится в заголовке фрагмента до того, как будет записан новый код. При написании кода в формате JSON (по сравнению с Markdown) требуется дополнительное экранирование символов новой строки и кавычек.
Мы предлагаем следующие форматы инструментов:
- Дайте модели достаточно токенов, чтобы она могла «подумать», прежде чем загнать себя в угол.
- Сохраняйте формат, близкий к тому, который модель естественным образом воспринимает в текстах в интернете.
- Убедитесь, что нет никаких «накладных расходов» на форматирование, например необходимости вести точный подсчёт тысяч строк кода или экранировать любой записываемый код.
Одно из эмпирических правил заключается в том, чтобы оценить, сколько усилий уходит на создание человеко-машинных интерфейсов (ЧМИ), и запланировать потратить столько же усилий на создание хороших агентных компьютерных интерфейсов (АКИ). Вот несколько советов о том, как это сделать:
- Поставьте себя на место модели. Понятно ли, как использовать этот инструмент, исходя из его описания и параметров, или вам нужно хорошенько подумать? Если да, то, скорее всего, это справедливо и для модели. Хорошее описание инструмента часто включает примеры использования, пограничные случаи, требования к формату входных данных и чёткие границы с другими инструментами.
- Как можно изменить названия или описания параметров, чтобы сделать их более понятными? Представьте, что вы пишете отличную документацию для младшего разработчика в вашей команде. Это особенно важно при использовании множества похожих инструментов.
- Проверьте, как модель использует ваши инструменты. Запустите множество примеров входных данных в нашей рабочей среде, чтобы увидеть, какие ошибки допускает модель, и внесите изменения.
- Пока-ёкэ ваши инструменты. Измените аргументы так, чтобы было сложнее допустить ошибку.
При создании нашего агента для SWE-bench мы потратили больше времени на оптимизацию инструментов, чем на саму подсказку. Например, мы обнаружили, что модель допускает ошибки при использовании инструментов с относительными путями к файлам после того, как агент выходит за пределы корневого каталога. Чтобы исправить это, мы изменили инструмент так, чтобы он всегда требовал абсолютных путей к файлам, и обнаружили, что модель безупречно использует этот метод.